Overview
Reinforcement learning (RL) is a branch of machine learning in which an agent learns to make decisions by performing actions in an environment and receiving feedback in the form of rewards or penalties. The goal of the agent is to learn a policy that maximizes the expected cumulative reward over time. Unlike supervised learning, where the correct answers are provided, reinforcement learning relies on the agent discovering optimal behavior through exploration and exploitation of the environment Sutton & Barto, 2018.
Historical Background
The conceptual foundations of reinforcement learning can be traced to behavioral psychology, particularly the study of operant conditioning by B.F. Skinner in the 20th century. Early computational models, such as dynamic programming and temporal difference learning, were developed in the 1950s and 1980s, respectively. The formalization of RL as a distinct field emerged in the late 20th century, with key contributions from researchers such as Richard S. Sutton and Andrew G. Barto Sutton & Barto, 2018.
Core Concepts
Agent and Environment
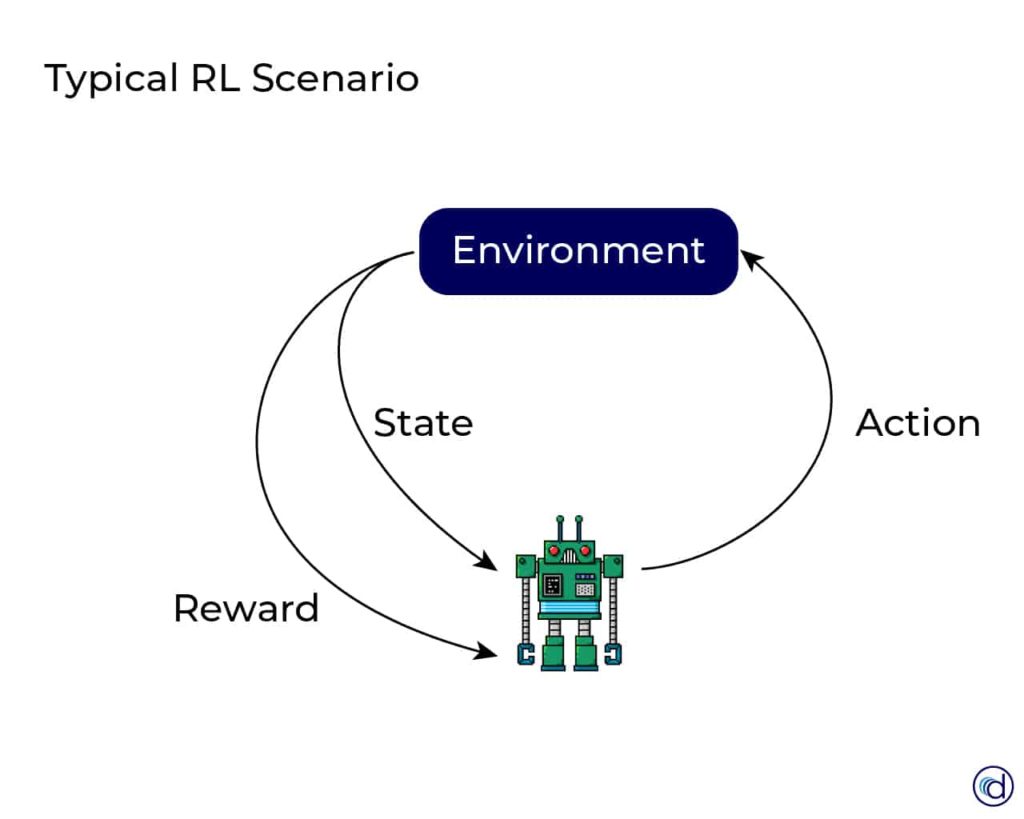
In RL, the agent interacts with an environment, which is typically modeled as a Markov Decision Process (MDP). At each time step, the agent observes the current state, selects an action, and receives a reward and a new state from the environment Sutton & Barto, 2018.
Policy, Reward, and Value Functions
- –Policy: A policy defines the agent's behavior, mapping states to actions.
- –Reward Signal: The reward is a scalar feedback signal indicating the immediate benefit of an action.
- –Value Function: The value function estimates the expected cumulative reward from a given state or state-action pair, guiding the agent toward long-term success.
Exploration vs. Exploitation
A central challenge in RL is balancing exploration (trying new actions to discover their effects) and exploitation (choosing actions known to yield high rewards). Various strategies, such as epsilon-greedy and softmax action selection, are used to address this trade-off Sutton & Barto, 2018.
Algorithms
Model-Free Methods
Model-free algorithms do not assume knowledge of the environment's dynamics. Key examples include:
- –Q-Learning: An off-policy algorithm that learns the value of action-state pairs
Watkins & Dayan, 1992.
- –SARSA: An on-policy algorithm that updates value estimates based on the agent's current policy.
Model-Based Methods
Model-based algorithms attempt to learn a model of the environment's dynamics and use it to plan future actions. These methods can be more sample-efficient but often require more computation Sutton & Barto, 2018.
Policy Gradient Methods
Policy gradient methods directly optimize the policy by adjusting its parameters in the direction that increases expected reward. These methods are particularly effective in high-dimensional or continuous action spaces OpenAI, 2024.
Deep Reinforcement Learning
Deep reinforcement learning combines RL with deep neural networks, enabling agents to learn directly from high-dimensional sensory inputs such as images. Notable breakthroughs include Deep Q-Networks (DQN) and AlphaGo, which demonstrated superhuman performance in complex games DeepMind, 2024.
Applications
Reinforcement learning has been successfully applied in a variety of domains:
- –Game Playing: RL agents have achieved human-level or superhuman performance in games such as Go, chess, and Atari video games
DeepMind, 2024.
- –Robotics: RL is used for autonomous control, manipulation, and navigation tasks in robotics
IEEE Transactions on Neural Networks and Learning Systems, 2024.
- –Autonomous Vehicles: RL algorithms are employed for decision-making and control in self-driving cars.
- –Resource Management: RL is applied in optimizing resource allocation in computer systems and telecommunications.
Challenges and Limitations
Despite its successes, reinforcement learning faces several challenges:
- –Sample Efficiency: Many RL algorithms require large amounts of data to learn effective policies.
- –Stability and Convergence: Training can be unstable, especially in deep RL.
- –Reward Design: Crafting appropriate reward functions is often non-trivial and can significantly impact agent behavior.
- –Generalization: RL agents may struggle to generalize learned behaviors to new, unseen environments
Sutton & Barto, 2018.
Future Directions
Research in reinforcement learning continues to advance, with ongoing work in areas such as multi-agent systems, hierarchical RL, transfer learning, and safe RL. The integration of RL with other machine learning paradigms, such as supervised and unsupervised learning, is also an active area of exploration OpenAI, 2024.