Overview
Embedding models are machine learning techniques that map complex, high-dimensional data into lower-dimensional vector spaces. This transformation captures semantic relationships within the data, facilitating efficient processing and analysis. By representing data such as words, images, or audio as numerical vectors, embedding models enable machines to understand and manipulate information in a manner akin to human cognition.
Types of Embedding Models
Word Embeddings
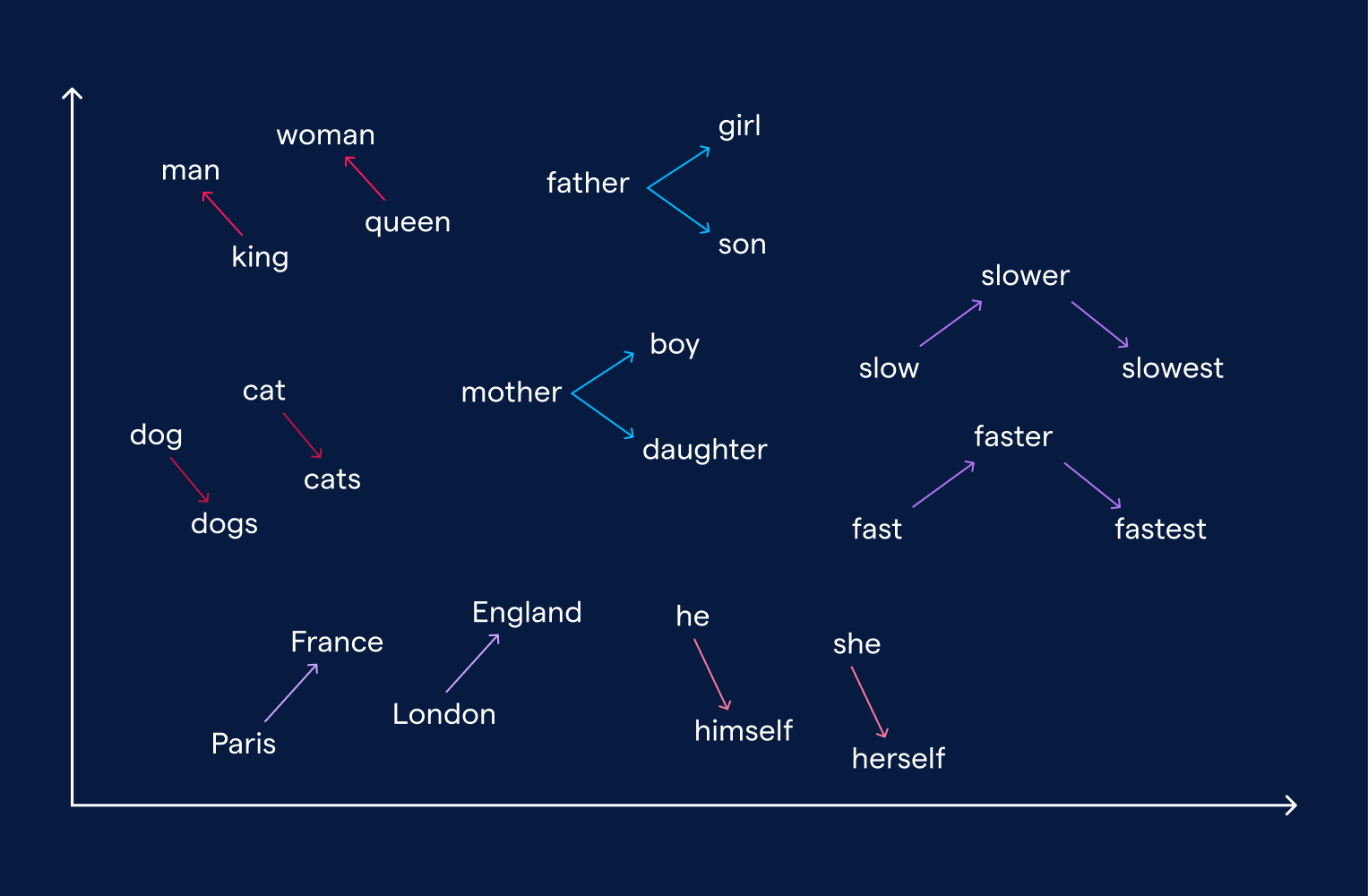
Word embeddings represent words as continuous vectors in a multi-dimensional space, capturing semantic similarities between them. Techniques like Word2Vec, developed by Google, learn these representations by analyzing large text corpora, positioning similar words closer together in the vector space. For instance, the vectors for "king" and "queen" would be proximate, reflecting their related meanings.
Sentence and Document Embeddings
Beyond individual words, models like Doc2Vec and BERT (Bidirectional Encoder Representations from Transformers) generate embeddings for entire sentences or documents. BERT, introduced by Google, considers the context of words bidirectionally, leading to more nuanced representations that improve tasks such as text classification and question answering.
Image Embeddings
In computer vision, convolutional neural networks (CNNs) are employed to create image embeddings. Models like ResNet (Residual Networks) extract features from images, enabling tasks like object detection and image classification. These embeddings allow machines to recognize and process visual information effectively.
Audio Embeddings
Audio embeddings convert sound data into numerical vectors, capturing features like tone and pitch. Techniques such as Wav2Vec facilitate applications in speech recognition and music analysis by representing audio signals in a form suitable for machine learning models.
Graph Embeddings
Graph embeddings represent nodes and edges of a graph in a continuous vector space, preserving the graph's structural information. Methods like Node2Vec and GraphSAGE are utilized in social network analysis and recommendation systems to understand relationships and predict connections within networks.
Applications
Embedding models have a wide range of applications across various domains:
- –
Natural Language Processing (NLP): Word and sentence embeddings enhance tasks like sentiment analysis, machine translation, and information retrieval by capturing the semantic meaning of text.
- –
Recommendation Systems: By embedding users and items into a shared vector space, systems can predict user preferences and suggest relevant products or content.
- –
Computer Vision: Image embeddings enable tasks such as facial recognition, object detection, and image similarity searches.
- –
Speech Recognition: Audio embeddings facilitate the conversion of spoken language into text by capturing the nuances of speech patterns.
- –
Graph Analysis: Graph embeddings assist in understanding complex networks, aiding in tasks like community detection and link prediction.
Key Techniques
Several techniques are fundamental in generating embeddings:
- –
Principal Component Analysis (PCA): A dimensionality reduction method that transforms high-dimensional data into a lower-dimensional form while preserving variance.
- –
Singular Value Decomposition (SVD): Decomposes a matrix into singular vectors and values, capturing essential structures in the data.
- –
Autoencoders: Neural networks designed to learn efficient codings of input data, often used for generating embeddings by compressing data into a latent space.
Challenges and Considerations
While embedding models offer significant advantages, they also present challenges:
- –
Dimensionality Selection: Choosing the appropriate dimensionality for embeddings is crucial; too few dimensions may lose information, while too many can lead to overfitting.
- –
Interpretability: High-dimensional embeddings can be difficult to interpret, making it challenging to understand the features they capture.
- –
Computational Resources: Training embedding models, especially on large datasets, requires substantial computational power and memory.
Future Directions
Advancements in embedding models continue to evolve, with research focusing on:
- –
Contextual Embeddings: Developing models that better capture context-dependent meanings, enhancing performance in NLP tasks.
- –
Multimodal Embeddings: Creating embeddings that integrate multiple data types, such as text and images, to improve tasks like image captioning and cross-modal retrieval.
- –
Efficient Training Methods: Innovating techniques to reduce the computational burden of training embedding models, making them more accessible for various applications.
Embedding models remain a cornerstone of machine learning, enabling the transformation of complex data into forms that machines can process and understand, thereby driving progress across numerous fields.